

Не толкова отдавна публикувахме статия за свързване на популярни безплатни услуги за съхранение в облак към сървър с CentOS 7. В тази статия ще покажем как можете да използвате данни за съхранение, за да архивирате данни от вашия сървър. Използвам тези скриптове за допълнително архивиране на файлове на сайтове и база данни от моя VPS сървър на Linux.
Съдържание:
- Архивиране на данни в OneDrive от Linux CentOS
- Резервно копие на Google Drive.
- Резервно копие на Yandex.Disk от Linux
Архивиране на данни в OneDrive от Linux CentOS
Ще архивираме сайта и базата данни, както и ще проверим "възрастта" на архивирането (изтрийте резервните копия преди седмица) и ще изпратим доклад с пълната информация за изпълнение на скрипта на пощата. Всъщност самият баш скрипт:
#! / bin / bash
# Копирайте файловете на сайта във временна директория
rsync -avzr - прогрес / var / www / html / / var / www / tmp / backup / >> result.txt
# Извършете демпф на базата данни, поставете файла на dump във временна директория
mysqldump joomla> /var/www/tmp/backup/backup.sql
# Създайте архив на временна директория
tar -cvzf архивиране - $ (дата +% y% m% d) .tar.gz - имена на имената / var / www / tmp / backup / >> резултат.txt
# Проверете облачната директория за стари архиви, ако има такива, изтрийте
find / root / OneDrive / backup / -name "backup * .tar.gz" -mtime +7 -exec rm -f \; >> резултат.txt
# Копирайте създадения преди това архив в облака
rsync -avzr --progress /root/bin/backup*.tar.gz / root / OneDrive / backup / >> result.txt
# Изтриване на архив от директория на скриптове
rm -rf /root/bin/backup*.tar.gz >> резултат.txt
# Синхронизираме с облака с -local-first flag, което ще ни позволи да премахнем старите архиви от облака, ако ги изтрием локално и качим нови резервни копия
onedrive - локално първо - синхронизиране >> result.txt
# Изпращаме имейл с прикачен файл, където се показва целият процес на архивиране (заменете с вашата пощенска кутия)
ехо "Вижте файла за грешки и ги поправете" | mail -a "/root/bin/result.txt" -s "Създаден бекъп" - ******@gmail.com
# Почистваме директории от ненужни файлове
rm -rf /root/bin/result.txt && rm -rf / var / www / tmp / backup / *
Преди да напиша тази статия, създадох няколко архиви, за да мога да демонстрирам, че скриптът работи правилно (изтрива стари архиви и качва нови).
Тичах 3 пъти ръчно. Създадени бяха няколко архиви, след което всички те бяха изпратени успешно в облака:
ls -la / root / OneDrive / архивиране /
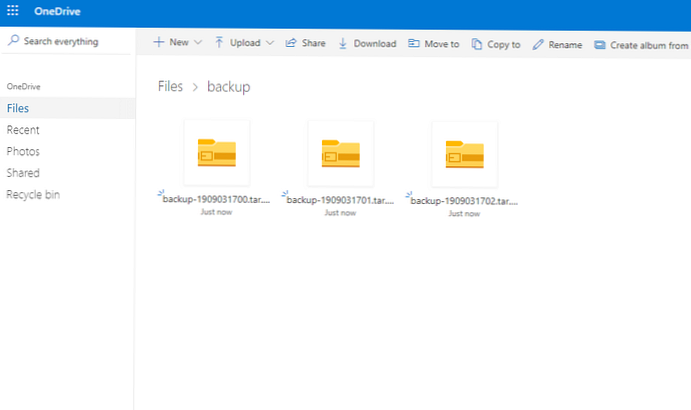
общо 28260 drwxr-xr-x 2 корен корен 102 септември 3 17:02. drwxr-xr-x 5 корен корен 94 септември 3 11: 15 ... -rw-r - r-- 1 корен корен 9643081 септември 3 17:00 backup-1909031700.tar.gz -rw-r - r-- 1 root root 9643082 Sep 3 17:01 backup-1909031701.tar.gz -rw-r - r-- 1 root root 9643083 Sep 3 17:02 backup-1909031702.tar.gz Инициализиране на двигателя за синхронизация ... Синхронизиране на промените от локалния път първо преди да изтеглите промени от OneDrive ... Изтриване на елемент от OneDrive: архивиране / архивиране-1909031700.tar.gz Изтриване на елемент от OneDrive: архивиране / резервно копие-1909031701.tar.gz Изтриване на елемент от OneDrive: резервно копие / резервно копие-1909031702.tar.gz Качване нов файл ./backup/backup-1909031704.tar.gz ... Качване 100% | oooooooooooooooooooooooooooooooooooooooooo | Съставено в 00:00:04 свършено. Обработка на 6 промени
Проверка на облака и трите архива с архивиране тук:
Следващата стъпка изтрих създадените архиви от директорията на сървъра и пуснах отново скрипта. Списък на съдържанието на директорията на сървъра:
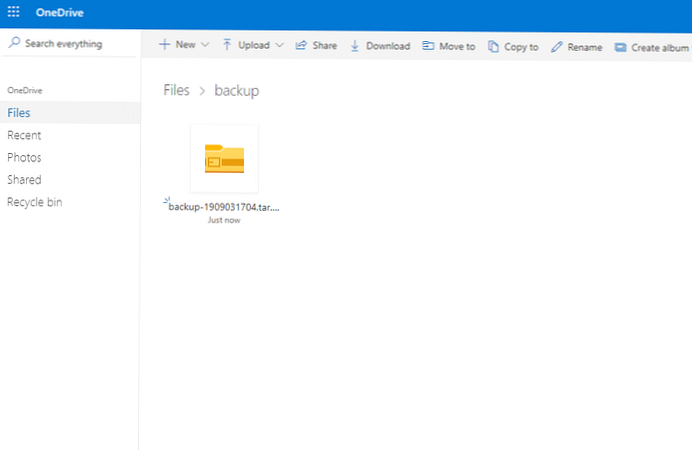
ls -la / root / OneDrive / архивиране /
общо 9420 drwxr-xr-x 2 корен на корен 38 септември 3 17:04. drwxr-xr-x 5 root root 94 Sep 3 11: 15 ... -rw-r - r-- 1 root root 9643082 Sep 3 17:04 backup-1909031704.tar.gz
Влязъл в уеб интерфейса на OneDrive, видях, че резервните копия са изтрити и оттам автоматично.
Освен това, след пускане на скрипта, получих имейл:
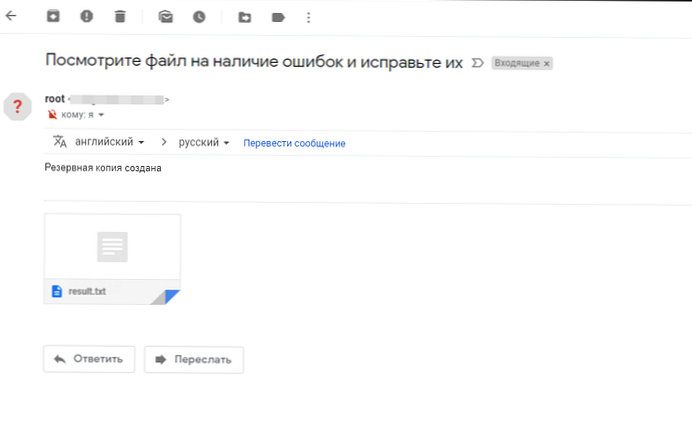 Това е всичко, това е, архивирането на OneDrive приключи..
Това е всичко, това е, архивирането на OneDrive приключи..
Резервно копие на Google Drive.
Архивирането до Google Drive в Se се оказа не толкова лесно, колкото при OneDrive, въпреки че самата настройка е доста проста. Основният проблем възникна с премахването на стари архиви от Google Drive, тъй като директорията за съхранение не е монтирана на сървъра. Но след дълго проучване на помощната програма за управление, успяхме да надстроим предишния си скрипт.
#! / bin / bash
# изтрийте файлове по-стари от 7 дни с g.drive
/ usr / sbin / drive list -q "modifiedDate < '$(date -d '-7 day"+%Y-%m-%d')'" | cut -d" " -f1 - | xargs -L 1 drive delete -i
rsync -avzr - прогрес / var / www / html / / var / www / tmp / backup / >> result.txt
mysqldump joomla> /var/www/tmp/backup/backup.sql
tar -cvzf архивиране - $ (дата +% Y% m% d) .tar.gz - имена на имената / var / www / tmp / backup / >> резултат.txt
# качете файла в g.drive
/ usr / sbin / drive upload -f /root/bin/backup*.tar.gz >> result.txt
rm -rf /root/bin/backup*.tar.gz >> резултат.txt
ехо "Вижте файла за грешки и ги поправете" | mail -a "/root/bin/result.txt" -s "Създаден бекъп" - ******@gmail.com
rm -rf /root/bin/result.txt
rm -rf / var / www / tmp / backup / *
Не рисувах останалите стъпки в сценария, тъй като те се повтарят с предишните.
Изпълнявайки скрипта, той беше изпълнен:
sh backup_gdrive.sh
Премахнат файл 'DSC_2151.NEF' Премахнат файл 'DSC_2153.NEF' Премахнат файл 'DSC_2159.NEF' Премахнат файл 'DSC_2226.NEF' Премахнат файл 'DSC_2225.NEF'
Проверете наличието на файл в Google Диск: списък за шофиранеId Размер на заглавието Създаден 1oay3-FAWBZRjHtma1cRTLrOvf3t8hRpD backup-20190904.tar.gz 9.6 MB 2019-09-04 14:43:25
От уеб интерфейса е видимо както от конзолата:
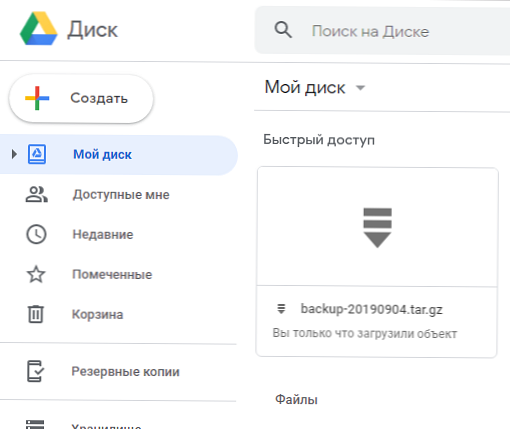
По този начин получаваме скрипт, който проверява за наличие на стари архиви в облака на Google Drive, изтрива ги, ако отговарят на изискванията, след това създава резервно копие на сайта и го изпраща на същия облак.
Резервно копие на Yandex.Disk от Linux
Оставих това облачно хранилище за лека закуска, тъй като архивирането в Yandex.Disk е най-лесното, защото Монтирахме облачното хранилище на Yandex чрез WebDav като отделно дисково устройство. Методът е същият, изпълняваме скрипта, само с малка разлика, не е необходимо да синхронизираме или качваме файлове със специални команди, работим като с нормална сървърна директория. Синхронизирането на директории се извършва с помощта на rsync. Сценарият ще изглежда така:
#! / bin / bash
rsync -avzr - прогрес / var / www / html / / var / www / tmp / backup / >> result.txt
mysqldump joomla> /var/www/tmp/backup/backup.sql
tar -cvzf архивиране - $ (дата +% Y% m% d) .tar.gz - имена на имената / var / www / tmp / backup / >> резултат.txt
find / mnt / yad / -name "архивиране * .tar.gz" -mtime +7 -exec rm -f \; >> резултат.txt
rsync -avzr --progress /root/bin/backup*.tar.gz / mnt / yad / >> result.txt
rm -rf /root/bin/backup*.tar.gz >> резултат.txt
ехо "Вижте файла за грешки и ги поправете" | mail -a "/root/bin/result.txt" -s "Създаден бекъп" - ****@gmail.com
rm -rf /root/bin/result.txt
rm -rf / var / www / tmp / backup / *
Все едно, само без допълнителни команди. Ако имате други пътища до облачно съхранение, променете скрипта на вашия.
В края на статията бих искал да добавя. Поставих тези скриптове в отделна директория и ги пуснах на короната. Ако дисковото пространство на вашите облачни дискове често ви позволява да създавате резервни копия, да ги създавате възможно най-често, препоръчвам поне веднъж на 3 дни. Използвайте ресурсите си за съхранение в облак 100%.
Примери за задачи в короната:
0 0 * * 6 /root/bin/backup.sh - стартирайте резервния скрипт всяка събота в 00-000 0 * / 3 * * /root/bin/backup.sh - стартирайте скрипта за архивиране на всеки 3 дни в 00-00
И така нататък, конфигурирайте архиви, както искате, когато натоварването на сървъра е минимално.


{kind=link}