

В тази статия ще разгледаме конфигурирането на аварийна конфигурация от два прокси прокси сървъра, за да могат потребителите да имат достъп до Интернет от корпоративна мрежа с просто балансиране на натоварването чрез Round Robin DNS. За да изградим конфигурация при отказ, ще създадем HA клъстер, използвайки keepalived.
HA клъстер - Това е група сървъри с вградена съкращаване, която се създава, за да се сведе до минимум прекъсването на приложението в случай на хардуерни или софтуерни проблеми на един от членовете на групата. Въз основа на това определение за работата на HA клъстера е необходимо да се приложи следното:
- Проверка на състоянието на сървърите;
- Автоматично превключване на ресурси в случай на повреда на сървъра;
И двете от тези задачи позволяват спазването им. Keepalived - системен демон на Linux системи, който позволява организиране на откази за отказ на услуга и балансиране на натоварването. Толерантност на повредите се постига благодарение на „плаващия“ IP адрес, който се превключва към резервния сървър в случай на повреда на основния. Протоколът се използва за автоматично превключване на IP адреси между keepalived сървъри VRRP (Virtual Router Redundancy Protocol), той е стандартизиран, описан в RFC (https://www.ietf.org/rfc/rfc2338.txt).
Съдържание:
- Принципи на VRRP
- Инсталирайте и конфигурирайте keepalived на CentOS
- Keepalived: следете здравето на приложението и интерфейса
- Keepalived: тест при отказ
Принципи на VRRP
На първо място, трябва да вземете предвид теорията и основните дефиниции на VRRP протокола.
- VIP - Виртуален IP, виртуален IP адрес, който може автоматично да превключва между сървъри в случай на отказ;
- Master - сървърът, на който в момента VIP е активен;
- Резервно копие - сървъри, към които VIP ще превключи, ако съветникът не успее;
- VRID - ID на виртуален рутер, сървърите, обединени от общ виртуален IP (VIP), образуват така наречения виртуален рутер, чийто уникален идентификатор приема стойности от 1 до 255. Сървърът може едновременно да се състои от няколко VRID, с уникални виртуални IP адреси за всеки VRID.
Общ алгоритъм на работа:
- Главният сървър изпраща VRRP пакети до запазения адрес за излъчване на многоадресен (мултикаст) 224.0.0.18 с определен интервал и всички подчинени сървъри слушат този адрес. Изпращането по многостранни съобщения е, когато изпращачът е един и може да има много получатели.
Важно е. За да работят сървърите в режим на множествено предаване, мрежовото оборудване трябва да поддържа предаването на трафик за многоадресна комуникация. - Ако подчиненият сървър не получава пакети, той стартира процедурата за избор на главно и ако премине в главно състояние по приоритет, активира VIP и отрови безвъзмезден ARP. Безплатни ARP е специален вид ARP отговор, който актуализира MAC таблицата на свързани превключватели, за да ви информира за промяната на собствеността на виртуалния IP адрес и mac адреса за пренасочване на трафика.
Инсталирайте и конфигурирайте keepalived на CentOS
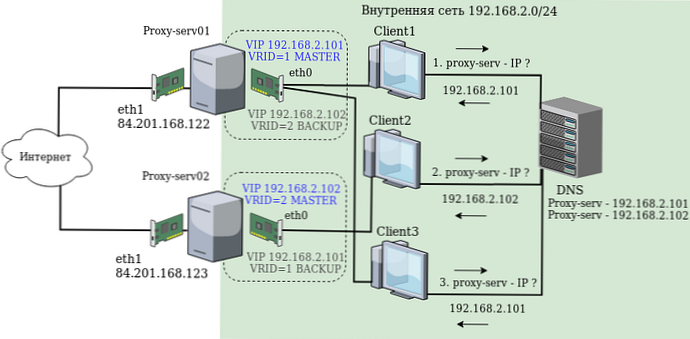
Инсталирането и конфигурирането ще се извършат на пример proxy-serv01 сървъри и прокси-serv02 на Centos 7 с инсталиран калмар. В нашата схема ще използваме най-простия метод за балансиране на натоварването (балансиране) - Round Robin DNS. Този метод предполага, че за едно име няколко DNS адреса са регистрирани в DNS и клиентите, при поискване, получават един адрес наведнъж, а след това друг. Следователно ще се нуждаем от два виртуални IP адреса, които ще бъдат регистрирани в DNS със същото име и с които клиентите в крайна сметка ще се свържат. Мрежова схема:
Всеки Linux сървър има два физически мрежови интерфейса: eth1 с бял IP адрес и достъп до Интернет, и eth0 в локалната мрежа.
Следните се използват като реални IP адреси на сървъра:
192.168.2.251 - за прокси-сървър01
192.168.2.252 - за прокси-сървър02
Следните се използват като виртуални IP адреси, които автоматично ще превключат между сървъри в случай на повреда:
192.168.2.101
192.168.2.102
Инсталирайте пакета keepalived на двата сървъра с помощта на командата:
yum инсталирате keepalived
След като инсталацията приключи и на двата сървъра, редактирайте конфигурационния файл
/etc/keepalived/keepalived.conf
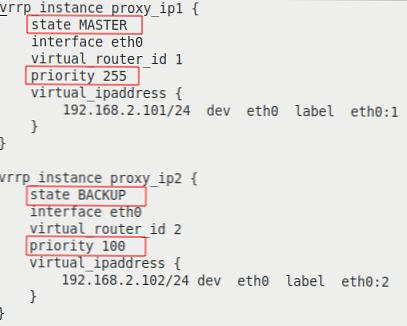
Цветно подчертани линии с различни параметри:
| на прокси-serv01 сървъра | на сървъра proxy-serv02 |
 | 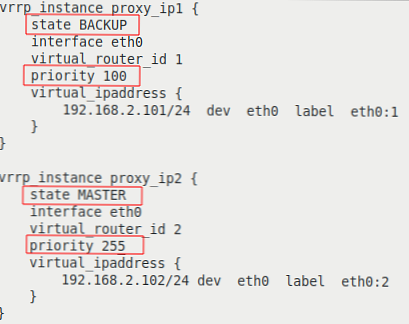 |
Ще анализираме опциите по-подробно:
- vrrp_instance - Раздел за определяне на инстанция VRRP;
- състояние - първоначално състояние при стартиране;
- интерфейс - интерфейсът, върху който ще работи VRRP;
- virtual_router_id - уникален идентификатор на VRRP инстанцията, трябва да съвпада на всички сървъри;
- приоритет - задава приоритет при избора на MASTER, сървърът с най-висок приоритет става MASTER;
- virtual_ipaddress - блок от виртуални IP адреси, които ще бъдат активни на сървъра в състояние MASTER. Трябва да съвпада на всички сървъри в инстанцията VRRP.
Ако текущата мрежова конфигурация не позволява мултикаст, keepalived има възможност да използва unicast, т.е. изпращайте VRRP пакетите директно към посочените в списъка сървъри. За да използвате unicast, ще ви трябват опции:
- unicast_src_ip - източник на адрес за VRRP пакети;
- unicast_peer - блок от IP адреси на сървъри, до които ще бъдат изпращани VRPP пакети.
По този начин нашата конфигурация определя два VRRP инстанции, proxy_ip1 и proxy_ip2. По време на нормална работа proxy-serv01 сървърът ще бъде MASTER за виртуалния IP 192.168.2.101 и BACKUP за 192.168.2.102, а proxy-serv02 сървърът ще бъде MASTER за виртуалния IP 192.168.2.102 и BACKUP за 192.168.2.101.
Ако защитната стена е активирана на сървъра, тогава трябва да добавите разрешителни правила за многостранен трафик и vrrp протокол, използвайки iptables:
iptables -A INPUT -i eth0 -d 224.0.0.0/8 -j ACCEPT
iptables -A INPUT -p vrrp -i eth0 -j ACCEPT
Активираме стартирания и стартираме запазената услуга на двата сървъра:
systemctl enable keepalived
systemctl start keepalived
След стартиране на запазената услуга, виртуалните IP ще бъдат присвоени на интерфейсите от конфигурационния файл. Нека видим текущите IP адреси в интерфейса на eth0 сървъра:
ip a show eth0
На сървъра на прокси-serv01:

На прокси-serv02 сървъра:

Keepalived: следете здравето на приложението и интерфейса
Благодарение на VRRP протокола е възможно да се следи състоянието на сървъра, например, по време на пълна физическа повреда на сървъра или мрежов порт на сървъра или комутатора. Възможни са обаче и други проблемни ситуации:
- грешка в услугата на прокси сървъра - клиентите, които стигнат до виртуалния адрес на този сървър, ще получат съобщение в браузъра с грешка, че прокси сървърът не е наличен;
- отказ на втория интернет интерфейс - клиентите, които стигнат до виртуалния адрес на този сървър, ще получат съобщение в браузъра с грешка, че връзката не може да бъде установена.
За да се справим с горните ситуации, ще използваме следните опции:
- track_interface - следене на състоянието на интерфейсите; поставя екземпляра VRRP в състояние FAULT, ако един от изброените интерфейси е в състояние DOWN;
- track_script - наблюдение с помощта на скрипт, който трябва да върне 0, ако проверката завърши успешно, 1 - ако проверката не е успешна.
Актуализирайте конфигурацията, добавете наблюдение на интерфейса eth1 (по подразбиране, VRRP екземплярът ще провери интерфейса, към който е свързан, т.е. в текущата конфигурация eth0):
track_interface eth1
директива track_script изпълнява скрипт с параметрите, определени в блока vrrp_script, който има следния формат:
vrrp_script скрипт интервал - честотата на скрипта, по подразбиране 1 секундно падение - броя пъти, когато скриптът връща нулева стойност, при която да премине към повишаване на състоянието FAULT - броя пъти, когато скриптът връща нулева стойност, при която да излезе от състоянието на FAULT timeout, timeout, докато скриптът не върне резултат, след което връща нулева стойност. тегло - стойността, с която приоритетът на сървъра ще бъде намален в случай на преминаване към състояние FAULT. Стойността по подразбиране е 0, което означава, че сървърът ще премине в състояние FAULT след неуспешно изпълнение на скрипт за броя пъти, посочени от параметъра падение.
Конфигурирайте мониторинга на производителността на калмарите. Можете да проверите дали процесът е активен с помощта на командата:
калмари -к проверка
създаване на vrrp_script, с параметри на честотата на изпълнение на всеки 3 секунди. Този блок е дефиниран извън блоковете. vrrp_instance.
vrrp_script chk_squid_service script "/ usr / sbin / squid -k проверка" интервал 3
Добавете нашия скрипт за наблюдение, в двата блока vrrp_instance:
track_script chk_squid_service
Сега, ако услугата Squid proxy се провали, виртуалният IP адрес ще премине към друг сървър.
Можете да добавите допълнителни действия когато състоянието на сървъра се промени.
Ако Squid е конфигуриран да приема връзки от всеки интерфейс, т.е. http_port 0.0.0.0 128, тогава при смяна на виртуалния IP адрес няма да има проблеми, Калмарите ще приемат връзки на новия адрес. Но ако са конфигурирани конкретни IP адреси, например:
http_port 192.168.2.101 128 http_port 192.168.2.102път128
тогава Squid няма да знае, че се е появил нов адрес в системата, където трябва да слушате заявки от клиенти. За да се справите с подобни ситуации, когато трябва да извършите допълнителни действия при превключване на виртуалния IP адрес, keepalived съдържа възможност за изпълнение на скрипт, когато възникне събитие, когато състоянието на сървъра се промени, например от MASTER в BACKUP или обратно. Той се реализира чрез опцията:
известяване "път към изпълним файл"
Keepalived: тест при отказ
След като настроим виртуалния IP, ще проверим колко правилно се извършва обработката на грешка. Първият тест е да симулира отказ на един от сървърите. Прекъсваме от мрежата вътрешния мрежов интерфейс eth0 на прокси-serv01 сървъра, докато той спира да изпраща VRRP пакети, а прокси-serv02 сървърът трябва да активира виртуалния IP адрес 192.168.2.101. Ще проверим резултата с командата:
ip a show eth0
На сървъра на прокси-serv01:

На прокси-serv02 сървъра:
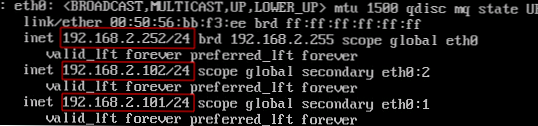
Както се очаква, proxy-serv02 сървърът активира виртуалния IP адрес 192.168.2.101. Нека да видим какво се е случило в регистрационните файлове с командата:
cat / var / log / messages | grep -i keepalived
| на прокси-serv01 сървъра | на сървъра proxy-serv02 |
Keepalived_vrrp [xxxxx]: Ядрото отчита: интерфейс eth0 DOWN Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Въвеждане на FAULT STATE Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) премахване на VIP протокола. Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Сега в състояние FAULT | Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Преход към MASTER STATE |
| Keepalived получава сигнал, че интерфейсът eth0 е в състояние DOWN и поставя екземпляра VRRP на proxy_ip1 в състояние FAULT, освобождавайки виртуалните IP адреси. | Keepalived поставя екземпляра VRRP на proxy_ip1 в състояние MASTER, активира адреса 192.168.2.101 на eth0 и изпраща безплатния ARP. |


И ще проверим, че след като интерфейсът eth0 на прокси сървъра сървър е свързан към мрежата, виртуалният IP 192.168.2.101 ще се върне обратно.
| на прокси-serv01 сървъра | на сървъра proxy-serv02 |
Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) принуждава нов избор на MASTER Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Преход към MASTER STATE Keepalived_vrrp [Keepback] VIP персони. Keepalived_vrrp [xxxxx]: Изпращане на безвъзмезден ARP на eth0 за 192.168.2.101 | Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Получена реклама с по-висок приоритет 255, нашата 100 Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Въвеждане на BACKUP STATE Keepalived_vrrp [xxxxx]: VRRPP__. |
| Keepalived получава сигнал за възстановяване на интерфейса eth0 и започва нов MASTER избор за VRRP екземпляр на proxy_ip1. След преминаване в състояние MASTER, той активира адреса 192.168.2.101 в интерфейса eth0 и изпраща безвъзмезден ARP. | Keepalived получава пакета с висок приоритет за VRRP инстанцията на proxy_ip1 и поставя proxy_ip1 в състояние BACKUP и освобождава виртуалните IP адреси. |
Вторият тест е да симулираме повреда на външния мрежов интерфейс, за това изключваме външния мрежов интерфейс eth1 на прокси-serv01 сървъра от мрежата. Ще проверим резултата от проверката от регистрационните файлове.
| на прокси-serv01 сървъра | на сървъра proxy-serv02 |
Keepalived_vrrp [xxxxx]: Ядрото отчита: интерфейс eth1 DOWN Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Въвеждане на FAULT STATE Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) премахване на VIP протокола. Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Сега в състояние FAULT | Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Преход към MASTER STATE Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Въвеждане на MASTER STATE Keepalived_vrrp [xxxxx]: VRRP_Insts Pro. Keepalived_vrrp [xxxxx]: Изпращане на безвъзмезден ARP на eth0 за 192.168.2.101 |
| Keepalived получава сигнал, че интерфейсът eth1 е в състояние DOWN и поставя екземпляра VRRP на proxy_ip1 в състояние FAULT, освобождавайки виртуалните IP адреси. | Keepalived поставя екземпляра VRRP на proxy_ip1 в състояние MASTER, активира адреса 192.168.2.101 на eth0 и изпраща безплатния ARP. |

Третата проверка е имитация на отказ на прокси услугата Squid, за това ръчно ще оставим услугата с командата: systemctl стоп калмари Ще проверим резултата от проверката от регистрационните файлове.
| на прокси-serv01 сървъра | на сървъра proxy-serv02 |
Keepalived_vrrp [xxxxx]: VRRP_Script (chk_squid_service) не е успешен Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Въвеждане на FAULT STATE Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1). Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Сега в състояние FAULT | Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Преход към MASTER STATE Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Въвеждане на MASTER STATE Keepalived_vrrp [xxxxx]: VRRP_Insts Pro. Keepalived_vrrp [xxxxx]: Изпращане на безвъзмезден ARP на eth0 за 192.168.2.101 |
| Скриптът за проверка на активността на прокси прокси сървъри не успя. Keepalived поставя екземпляра VRRP на proxy_ip1 в състояние FAULT, освобождавайки виртуалните IP адреси. | Keepalived поставя екземпляра VRRP на proxy_ip1 в състояние MASTER, активира адреса 192.168.2.101 на eth0 и изпраща безплатния ARP. |
И трите проверки преминаха успешно, конфигурираната конфигурация е конфигурирана правилно. В продължение на тази статия ще конфигурираме HA клъстера с помощта на Pacemaker и ще разгледаме спецификата на всеки от тези инструменти..
Краен конфигурационен файл /etc/keepalived/keepalived.conf за сървър прокси-serv01:
vrrp_script chk_squid_service script "/ usr / sbin / squid -k проверка" интервал 3 vrrp_instance proxy_ip1 състояние MASTER интерфейс eth0 virtual_router_id 1 приоритет 255 virtual_ipaddress 192.168.2.101/24 dev eth0 label 0: 1 track_interface eth1 track_interface eth1 track_interface eth1 track_interface eth1 track_interface eth1 track1interface eth1 track_interface eth1 track_interface eth1 track1interface eth1 track1interface eth1 track_interface eth1 track1interface eth1 track1interface eth1 track_interface eth1 track_interface eth1 track_interface eth1 track1interface eth1 track_interface eth1 vrrp_in substance proxy_ip2 състояние BACKUP интерфейс eth0 virtual_router_id 2 приоритет 100 virtual_ipadress 192.168.2.102/24 dev eth0 label eth0: 2 track_interface eth1 track_script chk_squid_service
Краен конфигурационен файл /etc/keepalived/keepalived.conf за сървър прокси-serv02:
vrrp_script chk_squid_service скрипт / usr / sbin / squid -k проверка "интервал 3 vrrp_instanca proxy_ip1 състояние BACKUP интерфейс eth0 virtual_router_id 1 приоритет 100 virtual_ipaddress 192.168.2.101/24 dev eth0 label 0: 1 track_interface eth1 track1interface eth1 track1interface eth1 track1interface eth1 track1interface eth1 vrrp_in substance proxy_ip2 състояние MASTER интерфейс eth0 virtual_router_id 2 приоритет 255 virtual_ipadress 192.168.2.102/24 dev eth0 label eth0: 2 track_interface eth1 track_script chk_squid_service


{kind=link}